React Hooks 体系设计
React Hooks 是 React 框架内的逻辑复用形式,因为其轻量、易编写的形态,必然会逐渐成为一种前端开发主流。但是在实际开发过程中,大部分的开发者对于 Hooks 的使用过于粗暴,缺乏设计感和复用性。
优质的专栏,把它整合一遍:https://zhuanlan.zhihu.com/fefame
不忘初心,始于分层
要知道之所以使用框架,一开始就是为了代码结构能够清晰明了
软件工程的经典论述:
We can solve any problem by introducting an extra level of indirection
没有什么问题是加一个层解决不了的。
这个论述自软件工程诞生起,至今依然是成立的,但要使之成立就必须有一个大前提:我们有分层
React 内置的 Hooks 提供了基础的能力,虽然本质上它也有一些分层,比如:
useStaste是基于useReducer的简化版本useMemo和useCallback事实上可以基于useRef实现
但是在实际应用时,我们可以将其视为一层,即基础的底层
因此,我们在实际的应用开发中,单纯地在组件里组合使用内置的 hook ,无疑是一种不分层的粗暴使用形式,这仅仅在表象上使用了 hook ,而无法基于 hook 达到逻辑复用的目标。
状态的分层设计
分层的形式固然千千万万五花八门,我选择了一种更为贴近传统,更能表达程序的本质的方法,以此将 hook 在纵向分为 6 个层,自底向上依次是:
- 最底层的内置
hook,不需要自己实现,官方直接提供 - 简化状态更新方式的
hook,比较经典的是引入immer来达到更方便地进行不可变更新的目的 - 引入「状态 + 行为」的概念,通过声明状态结构与相应行为快速创建一个完整上下文
- 对常见数据结构的操作进行封装,如数组的操作
- 针对通用业务场景进行封装,如分页的列表、滚动加载的列表、多选等
- 实际面向业务的实现
需要注意的是,这边仅仅提到了对状态的分层设计,事实上有大量的 hook 是游离于状态之外的,如基于 useEffect 的 useDocumentSize,或是基于 useRef 的 usePreviousValue、useStableMemo 等,这些 hook 是更加零散。独立的形态
使用 immer 更新状态
在第二层中,我们需要解决的问题是 React 要求的不可变数据更新有一定的操作复杂性,比如当我们需要更新对象的一个属性的时候,就需要
1 | const newValue = { |
这还只是一个简单对象,如果遇到复杂一些的对象,就大概率可能出现这样的情况:
1 | const newValue = { |
数组也不怎么容易,比如我想删除一个元素,就要这么来:
1 | const newArray = [...oldArray.slice(0, index), ...oldArray.slice(index + 1)] |
这些都是基于原有对象,进行数据的更新。
要解决这一些系列问题,我们可以使用 immer,利用 proxy 数据劫持的特性,将可变的数据更新映射为不可变的操作
状态管理额基础 hook 是 useState 和 useReducer,因此我们能封装成:
1 | const [state, setStatee] = useImmerState({ foo: { bar: 1 } }) |
以及:
1 | const [state, dispatch] = useImmerReducer( |
这一部分并没有太多的工作(immer 的 TS 类型是真的难写),但是提供了非常方便的状态更新能力,也便于在它之上的所有层的实现
状态与行为的封装
组件的开发,或者说绝大部分业务的开发,逃不出”一个状态 + 一系列行为“这个模式,而且行为与状态的结构是强相关的。这个模式在面向对象里我们称之为类:
1 | class User { |
而在 hook中,我们会这么做:
1 | const [name, setName] = useState('') |
这样子会出现一些问题:
- 太多的
useState和useCallback调用,重复的编码工作 - 如果不仔细阅读代码,很难找到状态与行为的对应关系
因此需要一个 hook 来帮助实现「一个状态」和「针对这个状态的行为」合并在一起:
1 | const userMethods = { |
可以看到,这样的声明十分接近面向对象的形态,有部分 React 开发者在粗浅地了解了函数式编程后,激进地反对面向对象,这显然是不可取的,面向对象依然是一种很好的封装和职责边界划分的形态,不一定要以其表面形态去实现,却也不可丢了其内在思想
数据结构的抽象
有了 useMethods 之后,我们已经可以快速地使用任何类型和结构的状态与 hook 整合,我们一定会意识到,有一部分状态类型是业务无关的,是全天下所有开发者所通用的,比如最基础的数据类型 number、string、Array 等
在数据结构的封装上,我们依然会面对几个核心问题:
- 部分数据结构的不可变操作相当复杂,比如不可变地实现
Array#splice,好在有immer合理地解决了这部分问题 - 部分操作的语义会发生变化,
setState最典型的是么有返回值,因此Array#pop只能产生「移除最后一个元素」的行为,而无法将移除的元素返回 - 部分类型是天生可变的,如
Set和Map,将之映射到不可变需要额外的工作
针对常用数据结构的抽象,在试图解决这些问题(第二个问题还真解决不了)的同时,也能扩展一些行为,比如:
1 | const [list, methods, setList] = useArray([]) |
而诸如 useSet 和 useMap 则会在每次更新时做一次对象复制的操作,强制实现状态的不可变。
社区的 hook 库中,很少看到有单独一个层实现数据结构的封装,实在是一种遗憾(不要封装啊喂),截止到今日,大致useNumber、useArray、useSet、useMap、useBoolean是已然实现的,其中还衍生出useToggle这样场景更狭窄的实现。而useString、useFunction和useObject能够提供什么能力还有待观察。
通用场景
在有了基本的数据结构后,可以对场景进行封装,这一点在阿里的@umijs/hooks体现的比较多,如useVirtualList就是一个价值非常大的场景的封装。
需要注意的是,场景的封装不应与组件库耦合,它应当是业务与组件之间的桥梁,不同的组件库使用相同的 hook 实现不同的界面,这才是一个理想的模式:
useTransfer实现左右双列表选择的能力useSelection实现列表上单选、多选、范围选择的能力useScrollToLoad实现滚动加载的能力
通用场景的封装非常的多,它的灵感可以来源于某一个组件库,也可以由团队的业务沉淀。一个充分的场景封装 hook 集合会是未来 React 业务开发的效率的关键之一。
分层总结
总而言之,在业务中暴力地直接使用 useState 等 hook 并不是一个值得提倡的方式,而针对状态这一块,精细地做一下分层,并在每个层提供相应的能力,是有助于组织 hook 库并赋能于业务研发效率的
hook 集合
@huse的 hook 集合,同样应用了分层的理念,也欢迎提出相应的需求,将于近期发布一个版本。
https://github.com/ecomfe/react-hooks
状态管理,状态粒度
状态无论什么时候都是 react 的重中之重
在有了 useState 之后,会发现状态被天生地拆散了,比如这是一个曾经的类组件:
1 | class TodoList extends Component { |
放到 hooks 上面,大概率就是这个样子:
1 | const TodoList = () => { |
老实说这算好的了,至少还搞了发起名的艺术,没有啥都叫 setFooBar
上面的这个转换方式无疑是正确的,不过现实并不总这么友好,状态拆分的时候,容易出现粒度控制不好的情况
粒度过细
如果按照标准的每一个状态对应一个 useState 的做法,自然是逻辑上正确的,但它容易造成状态粒度过细的问题
讲一个故事:
做一个表格,带一个选中功能,其中一个点是“按住 SHIFT 的同时点击一行可以选中一个区域”。
为了实现这个功能,我们需要 2 套逻辑:
- 当点击一行时,选中这一行
- 按 SHIFT 点击时,把上一次选中(或第一行)到当前行都选中
从这个场景我们能分析出一个结论:点击一行的时候,除了选中它,还需要记录最后一次选中的行为。为了简化这个模型,代码中先不管“取消选择”的效果:
1 | const SelectableList = () => { |
仔细看 useCallback 中的部分,我们能看到它会连续调用 2 个状态的更新,这会造成什么情况呢?每一次状态更新都触发一次渲染,会导致多次渲染的浪费嘛?
答案不好说,如果这件事发生在 React 管理的事件中,则更新会被合并起来,如果发生在其他场合(比如说异步结束时),则会使得 React 触发多次渲染。
一个相关示例:CodeSandbox 示例
但是这里我们着重讨论代码的组织和可读性问题
class 类组件时代,代码是这样的:
1 | class SelectableList extends Component { |
而不会这么写:
1 | class SelectableList extends Component { |
不否认 class 时代状态的集中管理是过于粗放的,但那个时代的状态更新粒度基本是没有问题的,所以在使用 hook 的时候不哟啊太过暴力的拆分状态,过于细粒度的拆分状态会导致代码阅读者难以理解状态间的关系,五星提升代码维护的难度
使用 Reducer 管理状态更新
现在搞清楚了状态粒度太细是不好的,所以不妨碍奖上面示例的状态重新再合并回来:
1 | const DEFAULT_SELECTION_STATE = { |
没什么难度,确实没什么难度
但是这种做法,依然会有一个问题:状态的更新与状态的声明距离过远。在这个例子中很难看出来,状态声明之后立刻旧有 useCallback 的调用去说明如何更新它。但是在实际编码中,我们很容易遇到状态的声明在第 1 行,而状态的更新在第 40+ 行这种情况,甚至是最终 JSX 中的某个箭头函数中。
在这样的代码中,阅读者想要搞清楚一个状态如何被使用、如何更新时十分困难的,这不仅降低了代码的可维护性,还给代码阅读者很大的挫败感,久而久之谁也不想接手这样的代码。
解决这个问题通常有两种方法:
- 把状态和更新封装到自定义的 Hook 当中去,比如就叫
useSelection - 使用
useReducer
第一种方法必不用说,能不能找到合适的粒度来实现自定义 hoook 就是对开发者素质的考研。但不少时候自定义 hook 作为一种解决方案还是过于重量级,虽然它仅仅是一个函数,但是依然需要阅读者去理解输入输出,使用 TypeScript 还可能造成类型定义上的额外工作。
使用 useReducer 可以在不少轻量级的场景中快速地将状态声明和状态更新放在一起,比如上面的例子可以这样改造:
1 | const SelectableList = () => { |
可以看到,通过 useReducer 我们传递一个函数,这个函数清晰地表达了 select 这个类型的操作,以及对应的状态更新。useReducer 的第二个参数也很好地说明了状态的结构。
当然如果我们使用 useImmer 或者 useMethods 会更容易实现:
1 | const SelectList = () => { |
状态过粗
反过来,状态也可能太粗,比如我们硬是将整个 class 的状态转移到一个 useState 中:
1 | const DEFAULT_STATE = { |
这样子写和 class 组件没两样,不建议这么干 ,当然数据流也许看起来会更清晰那么一点。
我们来考虑一下状态过粗的代价:
不过在此依然需要提一下状态过粗的代价,试想这样的组件:
1 | class UserInfo extends Component { |
然后我们还有一个这样的组件:
1 | class TodoList { |
这有什么问题呢?仔细去看 2 个组件,我们会发现它们其实是有共同的部分的:
- 有一个能展开/收起的状态,一个叫
isDetailVisible一个叫showFilterPanel。 - 有多个和异步过程有关的状态,比如
isBaseLoading和isDetailLoading。 - 有异步状态与结果的成对出现,比如
isBaseLoading配对baseInfo,isDetailLoading配对detailInfo。
但能得到这些结论,很大程度上归功于我给的代码过于精简,以及给了阅读者明确的“去发现”的目的。
试想你有一个超过 10 万行代码的项目,里面有 800 多个组件,有些组件有 1200 多行,你作为一个技术负责人空降到项目中,有信心去发现这些东西吗?反正我作为一个所谓的高 T,很实诚地说我做不到。
所以状态粒度过粗的问题就在于,它会隐藏掉可以复用的状态,让人不知不觉通过“行云流水地重复编码”来实现功能,离复用和精简越来越远。
当然,有时候保持一定程度上的重复是有意义的,比如使代码更具语义化,让人更看得懂代码在干啥,这在 class 时代特别明显。在 class 时代能解决这一问题的办法就是 HOC,比如我们做withLoading、withToggle、withRemoteData等等……
然后就会变成这样:
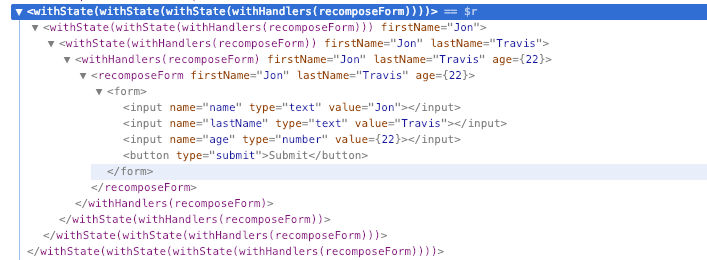
好在 hook 能比较合理地去解决这种嵌套问题。
合理设计粒度
本章讲了 2 个主要的论述:状态粒度太细不好,粒度太粗也不好。
在实际的业务里,比这复杂的多的事情天天在发生,远不是太细了合一合、太粗了分一分这么简单,大部分时候我们面对的是这样的情况:
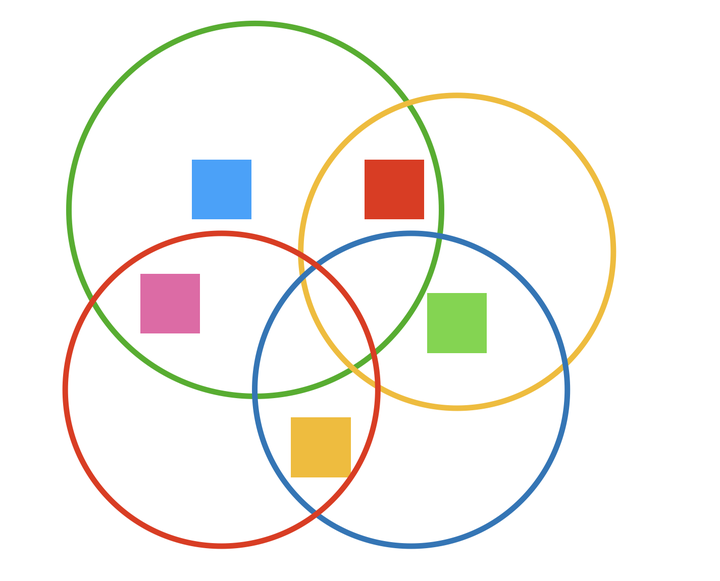
5 个状态 4 个组合操作,怎么设计粒度更合理,就慢慢折腾去吧。
最后送一个本文中提到的行选中功能的完整实现:
一直都在的 Ref
Ref 自 React 之初就不离不弃,最远古的字符串:
1 | <div ref=="root" /> |
到函数的形式:
1 | <div ref={(e) => (this.root = e)} /> |
到 createRef:
1 | class Foo extends Component { |
到 useRef:
1 | const Foo = () => { |
useRef 是 hook 一直绕不开的话题
DOM 与坑
最常见的 useRef 的用法就是保存一个 DOM 元素的引用,然后拿着 useEffect 去访问:
1 | const Foo = ({ text }) => { |
一段很常见的,运行十分良好的代码,但是如果我们将需求做一些变化,比如增加一个 visible: boolean 属性,然后变成:
1 | return visible ? <span ref={root}>{text}</span> : null |
将会发生什么呢?
很遗憾的是,这个组件如果第一次渲染的时候就指定了 visible={false} 的话,是无法正常工作的,具体可以参考这个 Sandbox 的示例:https://link.zhihu.com/?target=https%3A//codesandbox.io/s/conditional-ref-and-effect-t3pmo
这不仅仅存在于特定条件返回元素的情况之下,还包含了不少其他的场景:
- 根据条件返回不同的 DOM 元素,如
div和span换着来 - 返回的元素有
key属性且会变化
熟悉 useEffect 的人可能会发现,这个不执行的原因无非是没有传递依赖给 useEffect 函数,那么如果我们将 ref.current 传递过去呢?
1 | useLayoutEffect(() => { |
在一定的场景之下,比如上面的示例,这种方式是可行的,因为当 ref.current 变化的时候,代表着渲染的元素发生了变化,这个变化一定是由一次渲染引起的,也一定会触发对应的 useEffect 执行。但也存在不可行的时候,有些 DOM 的变化并非由渲染引起的,那么就不会有相应的 useEffect 被触发
这是 useRef 的一个神奇之处,虽然从名字上来说它应当被广泛用于和 DOM 元素简历关联,但往往拿它和 DOM 元素关联存在被坑的场景
Ref 的真实身份
让我们回到 class 时代看看 createRef 的用法:
1 | class Foo extends Component { |
仔细观察一下,createRef 是被用在什么地方的:它被放在了类的实例属性上面
由此得出,一个快速的结论:
ref 是一个与组件对应的 React 节点生命周期相同的,可用于存放自定义内容的容器
在 class 时代,由于㢟节点是通过 class 实例化而得,一次你可以在类实例上存放内容,这些内容随着实例化产生,随着 componentWillUnmount 销毁。但是在 hook 的范围下,函数组件并没有 this 和对应的实例,因此 useRef 作为这一能力的弥补,扮演者跨多次渲染存放内容的角色
每一个希望深入 hook 实践的开发者都必须记住这个结论,无法自如地使用 useRef 会让你失去 hook 将近一半的能力
一个定时器
在知晓了 ref 的真实身份之后,来看一个实际的例子,试图实现一个 useInterval 以定时执行函数:
1 | const useInterval = (fn, time) => |
这是一个基于 useEffect 的实现,如果你试图这样去使用它:
1 | useInterval(() => setCounter((counter) => counter + 1)) |
你会发现和你预期的“每秒计数加一”不同,这个定时器执行频率会变得非常诡异。因为你传入的 fn 每一次都在变化,每一次都导致 useEffect 销毁前一个定时器,打开一个新的定时器,所以简而言之,如果 1 秒之内没有重新渲染,定时器会被执行,而如果有新的渲染,定时器会重头再来,这让频率变得不稳定
为了修正频率的稳定性,我们可以要求使用者通过 useCallback将传入的 fn 固定起来,但是总有百密一疏,且这样的问题难以发现,此时我们可以拿出 useRef 换一种玩法:
1 | const useTimeout = (fn, time) => { |
把 fn 放进一个 ref 当中,它就可以绕过 useEffect 的闭包问题,让 useEffect 回调每一次都能拿到正确的、最新的函数,却不需要将它作为依赖导致定时器不稳定
React 官方也曾写过一些说明这一现象的博客,它们称 useRef 为“ hook 中的作弊器”,我想这个形容是准确的,所谓的“作弊”,其实是指它打破了类似 useCallback、useEffect 对闭包的约束,使用一个“可变的容器”让 ref 不需要成为闭包的依赖也可以在闭包中获取最新的内容
这也是 @huse/timeout 的具体实现,同时提供 useTimeout 和 useInterval,还附加一个 useStableInterval 会感知函数的执行时间(包括异步函数)并确保更加稳定的函数执行间隔
除此之外,@huse/poll 随时一个更为智能的定时实现,能够根据用户对页面的关注状态选择不同的频率,非常适用于定时拉取数据的场景
useRef 因为其可变内容、与组件节点保持相同生命周期的特点,其实有非常多的奇妙用法
回调 ref
为了解决 useRef 与 DOM 元素关联时的坑,最保守的方式就是使用函数作为 ref:
1 | const Foo = ({ text, visible }) => { |
函数的 ref 一定会在元素生成或销毁时被执行,可以确保追踪到最新的 DOM 元素。但它依然有一个缺点,例如我们想要实现这样的一个功能:
任意一段文字,通过计时器循环每个字符变色
假设我们突发奇想,不用 state 去控制变色的字符,就可以写出类似代码:
1 | useEffect( |
这是经典的 useEffect 的使用方式,返回一个函数来销毁之前的副作用。但是之前说了,useRef 和 useEffect 的配合是存在坑的,我们需要改造成函数 ref, 但是函数 ref 不支持销毁……
所以最后妥协了,依然使用 useEffect,但在渲染时确保只生成一个 DOM 元素,让 useEffect 一定能生效:
1 | return ( |
在这个场景下这样是可以“绕过”问题,并最终产出有效可用的代码,但是换一个场景呢?
使用 JQuery LightBox 插件,对一个图片增加点击预览功能
现在我们面对的是一个 img 元素,在没有 src 的时候这东西可不是简单的 display: none 就能安分守己的,你不得不采取 return null 的形式解决问题,那么你依然会提上 useEffect 的局限性
其实换个角度,我们缺少的是”将销毁函数保留下来以待执行”的功能,这是不是非常像 useTimeout 或者 useInterval 的功能呢?无非一个是延后一定时间执行,一个是延后到 DOM 元素销毁时执行
也就是说,我们完全可以用 useRef 本身去保存一个销毁函数,来实现与 useEffect 等价的能力:
1 | const noop = () => undefined |
可以看到,就是将之前的 useEffect 中的代码转移到了 useEffectRef 里(要用 useCallback包裹一下 ),代码很容易迁移,这算是 useRef 中的一个经典场景
通过 @huse/effect-ref 提供了 useEffectRef 能力,同时基于它在 @huse/element-size 中实现了 useElement、useElementResize 等 hook,能够有效提升业务开发的效率
玩坏 Ref
现在我们知道了 useRef 到底是个什么东西,它可以生成一个与组件节点生命周期的存放可变内容的容器
在这基础之上,可以使用 useRef 做很多东西
可变对象
更新一个数组或对象,用不可变的方式还是比较容易的:
1 | const newObj = { |
但是如果遇到 Map 和 Set 这类东西,它天生是可变的集合容器,如果这样写:
1 | const [items, setItems] = useState(new Set()) |
其实并不会触发组件更新,因为 items.add 前后并没有发生引用的改变,对 React 而言是同一个东西
一个办法是 immer 提供了针对 Map 和 Set 的更新,但是如果不想依赖 immer 该如何使用呢
其实我们可以用 useRef 来管理这样一个可变的状态,再想办法在状态更新的时候触发渲染就好。为此,我们需要一个可以直接触发组件更新的手段,让组件更新最简单的办法就是改变一个状态,那什么样的状态是每一次都会变化的呢?
1 | const useForceUpdate = () => useReducer((v) => v + 1, 0)[1] |
就这样搞定了,一个简单的递增的数字就行,通过 @huse/update 包中的 useForceUpdate 提供了这一能力
再然后,把它们拼在一起试试:
1 | const useSet = (initialEntries) => { |
这样一个简单的对 Set 的操作就实现了。不过我还不是很确定在并发模式下这东西是靠谱的,有什么结论的同学可以回复讨论一下。我们也通过@huse/collection提供了useArray、useMap、useSet等一系列集合相关的功能。
渲染计数
React 一个很让人头疼的问题是,它的性能是薛定谔的状态,哪怕脑子再清醒犀利,你也很难去判断一个组件在一顿操作猛如虎之下会更新几次、渲染几次,直到哪天性能崩得受不住了你才会回头捡起来看看情况。
用 Chrome 的性能面板去看情况当然非常好非常专业,但其实成本也不小,录制、分析都挺花精力的。有时候我们只想看看一个组件到底渲染不渲染,渲染了几次,大致对性能有一个了解;或者就想研究一下实现的自定义 hook 会不会造成组件过多的更新,所以我们希望能有这样的东西:
1 | const Foo = () => { |
然后操作一下,看看渲染次数有没有增长,快速地做一些定位和修复。
那么怎么实现这个东西呢,如果用状态的话:
1 | const useRenderTimes = () => { |
试一试?试试就逝世,保管你的浏览器卡得死死的关都不一定关得掉。这种在渲染中调用状态更新无疑会触发下一次渲染,形成一个死循环。
所以这时我们就要用到不会触发更新的可变容器:
1 | const useRenderTimes = () => { |
你看不仅仅不会触发更新了,代码也清晰直观了很多。在@huse/debug包中就有这个useRenderTimes,附带的还有很多用于调试的工具,不过要记得部署到生产环境前把这些代码去掉哦。
前一次值
在 class 组件的时代,我们有不少方法是能拿到“前一次更新的值”的,比如:
1 | class Foo extends Component { |
然后到了函数组件的时候,一下子全没了,全没了……这可不是说需要的场景就真的消失了,场景多着呢。
所以我们想办法把这个功能再找回来,原理也很简单,拿一个容器存着前一次的值不就好了:
1 | const usePreviousValue = (value) => { |
在@huse/previous-value中就给了这个能力,除此之外你还可以判断这个值是不是变了:
1 | usePreviousEquals(value, deepEquals) // 甚至还能自定义比较函数 |
组件更新源
你可能会说,React 不给你原始值一定有它设计的原因的,我肯定可以不用原始值活着的!那就来看一个比较经典的场景。
众所周知地再次强调,React 的更新和渲染基本就是个薛定谔状态,经常会有“你觉得我不会更新但我更新了呵呵呵”这样的尴尬情况出现,想知道组件为什么发生了更新是几乎每一个 React 开发者的渴望,甚至因此活生生出现了why-did-you-update这种东西。
不过why-did-you-update这东西的侵入性着实有些高,我们不如用 hook 来做一个简单的实现:
1 | const useUpdateCause = (props, print) => { |
通过简单地将当前值与上一次值比较来找到变化的原因,甚至可以做更精确地判断,比如@huse/debug中的 useUpdateCause就可以打印出这样的表格:
1 | ----------------------------------------------------------------------- |
帮助你一目了然地知道这些属性怎么变化。
对象追回
如果你通过useUpdateCause找到了一个属性变化,它虽然引用发生了变化,但是deepEquals列告诉你其实内容是一模一样的,这个变化完全不需要发生,要怎么办呢?
为了整个应用着想,我们会试图去追溯这个属性怎么来的,是不是在什么地方缺了useMemo或者reselect跨组件实例用了,没有做好缓存等等。但更多的时候,我们会发现外部的属性完全不是我们可控的,甚至可能来自于后端的返回,无论如何也做不到引用相同。
如果仅仅是触发了多次的更新,有些微的性能的损耗是小事,但如果这东西你用在了useEffect上,那可就要命了:
1 | useEffect( |
动不动就无限发请求,等着后端提刀子上门问候,这可不好。
我们要承认,这种情况在 React 生态里是随处可见的,甚至有为此而生的讨论串。有些开发者“机智”地用JSON.stringify去解决问题:
1 | const paramsString = JSON.stringify(params); |
这是有多蛋疼呢:
- 用
JSON.stringify本身就消耗了性能,性能还不一定低于一次渲染。 - 为了躲 ESLint 的规则检查,再用
JSON.parse转回来,再消耗一次性能。 - 我还没说
JSON.stringify对属性是不排序的,这样搞依然有可能出现内容相同但paramString不同的情况,你还得用fast-json-stable-stringify这样的库帮你解决问题。
所以在此我要展示一个神奇的 hook:
1 | const useOriginalCopy = (value, equals = shallowEquals) => { |
它到底干嘛了呢?简单来说就是“上一次的值与这一次内容相同的话,就把上一次还给你好啦”。这样就能把最原始的那个引用都一样的对象给拿到手了:
1 | const originalPrams = useOriginalCopy(params, deepEquals) // 用深比较 |
这样就能妥妥地安全使用。我们在@huse/previous-value里提供了这个能力,我愿意称之为我在 hook 领域上最伟大的发明,在社区上还没见过类似的实现。
使用useRef能实现的功能还有很多,比如@huse/derived-state能实现getDerivedStateFromProps的效果等等,学会使用它会给 React 领域的开发带来很大的便利和帮助。
看完后的学习目标
和学习 lodash 一样,在项目中引入 @huse 并熟练使用它
通过 熟练使用 => 设计轮子 => 参考比对 => 自我实现 的路径去深度掌握